本文共 10724 字,大约阅读时间需要 35 分钟。
转自
http://blog.csdn.net/21aspnet/article/details/50635225
memcached官网:
一.安装
下载
# wget http://www.memcached.org/files/memcached-1.4.25.tar.gz
解压
# tar xzvf memcached-1.4.25.tar.gz
#cd memcached-1.4.25
配置
#./configure --prefix=/usr/local/memcached --with-libevent=/usr
注意这里选择libevent的位置即可 例如你的是在–with-libevent=/usr/local/libevent/
# ./configure --prefix=/usr/local/memcached --with-libevent=/usr/local/libevent
编译安装
# make && make install
---------------需要依赖安装libevent-------------------
libevent官网
# wget https://github.com/libevent/libevent/releases/download/release-2.0.22-stable/libevent-2.0.22-stable.tar.gz
#
tar xzvf libevent-2.0.22-stable.tar.gz #
cd libevent-2.0.22-stable #
./configure --prefix=/usr/local/libevent #
make && make install 
----------------------------------
二.使用
启动
# /usr/local/memcached/bin/memcached -d -m 100 -uroot -l 0.0.0.0 -p 11211 -c 512 -P /usr/local/memcached/memcached.pid
启动参数:
- memcached 1.4.2
- -p <num> 监听的TCP端口(默认: 11211)
- -U <num> 监听的UDP端口(默认: 11211, 0表示不监听)
- -s <file> 用于监听的UNIX套接字路径(禁用网络支持)
- -a <mask> UNIX套接字访问掩码,八进制数字(默认:0700)
- -l <ip_addr> 监听的IP地址。(默认:INADDR_ANY,所有地址)
- -d 作为守护进程来运行。
- -r 最大核心文件限制。
- -u <username> 设定进程所属用户。(只有root用户可以使用这个参数)
- -m <num> 单个数据项的最大可用内存,以MB为单位。(默认:64MB)
- -M 内存用光时报错。(不会删除数据)
- -c <num> 最大并发连接数。(默认:1024)
- -k 锁定所有内存页。注意你可以锁定的内存上限。
- 试图分配更多内存会失败的,所以留意启动守护进程时所用的用户可分配的内存上限。
- (不是前面的 -u <username> 参数;在sh下,使用命令"ulimit -S -l NUM_KB"来设置。)
- -v 提示信息(在事件循环中打印错误/警告信息。)
- -vv 详细信息(还打印客户端命令/响应)
- -vvv 超详细信息(还打印内部状态的变化)
- -h 打印这个帮助信息并退出。
- -i 打印memcached和libevent的许可。
- -P <file> 保存进程ID到指定文件,只有在使用 -d 选项的时候才有意义。
- -f <factor> 块大小增长因子。(默认:1.25)
- -n <bytes> 分配给key+value+flags的最小空间(默认:48)
- -L 尝试使用大内存页(如果可用的话)。提高内存页尺寸可以减少"页表缓冲(TLB)"丢失次数,提高运行效率。
- 为了从操作系统获得大内存页,memcached会把全部数据项分配到一个大区块。
- -D <char> 使用 <char> 作为前缀和ID的分隔符。
- 这个用于按前缀获得状态报告。默认是":"(冒号)。
- 如果指定了这个参数,则状态收集会自动开启;如果没指定,则需要用命令"stats detail on"来开启。
- -t <num> 使用的线程数(默认:4)
- -R 每个连接可处理的最大请求数。
- -C 禁用CAS。
- -b 设置后台日志队列的长度(默认:1024)
- -B 绑定协议 - 可能值:ascii,binary,auto(默认)
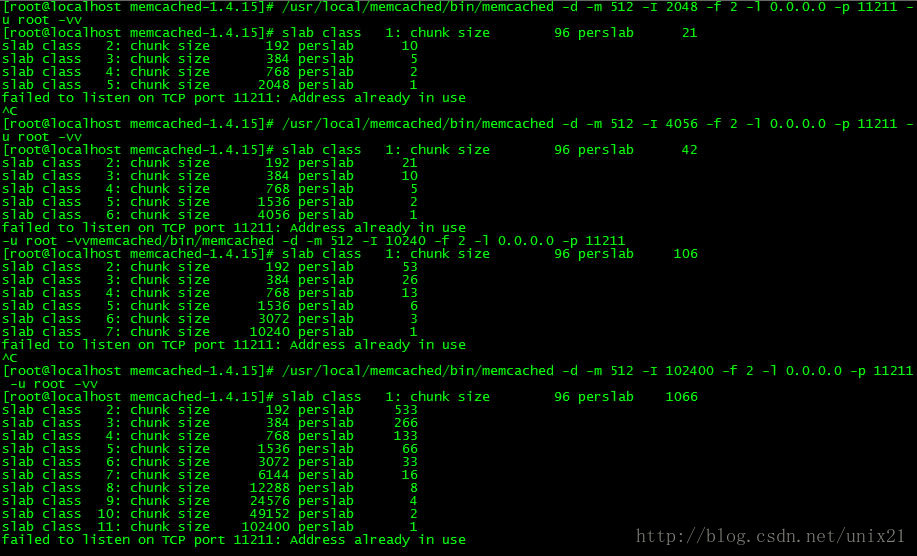
- -I 重写每个数据页尺寸。调整数据项最大尺寸。
查看详情
#ps aux|grep mem
输出pid
#cat /usr/local/memcached/memcached.pid
状态
# telnet 127.0.0.1 11211
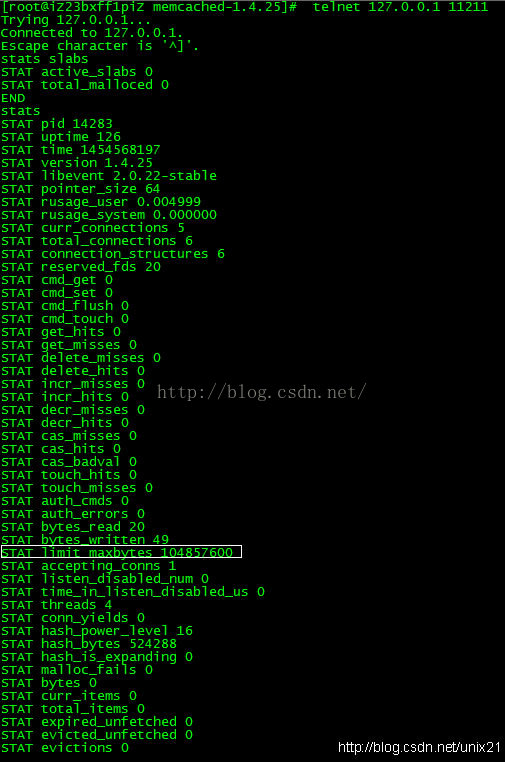
STAT limit_maxbytes就是最大内存是100M。
增加内存到200M
# /usr/local/memcached/bin/memcached -d -m 200 -uroot -l 0.0.0.0 -p 11211 -c 512 -P /usr/local/memcached/memcached.pid
先后2次查看内存使用
# top -n 1 |grep Mem

在启动memcached的时候可以通过-vv来查看slab的种类:
# /usr/local/memcached/bin/memcached -d -m 100 -uroot -l 0.0.0.0 -p 11211 -c 512 -P /usr/local/memcached/memcached.pid -vv
# /usr/local/memcached/bin/memcached -d -m 512 -l 0.0.0.0 -p 11211 -u root -vv
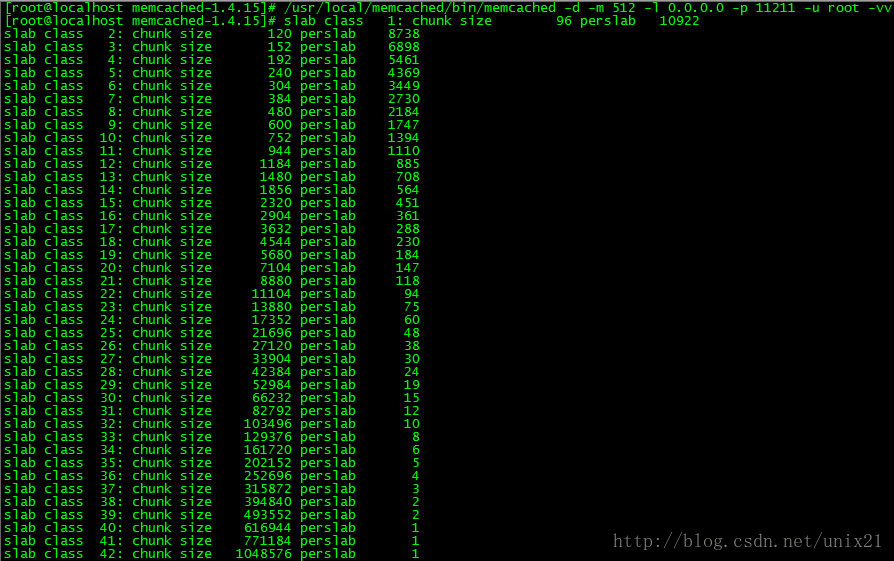
默认一个slab=1048576字节=1024K=1M
默认的truck是48
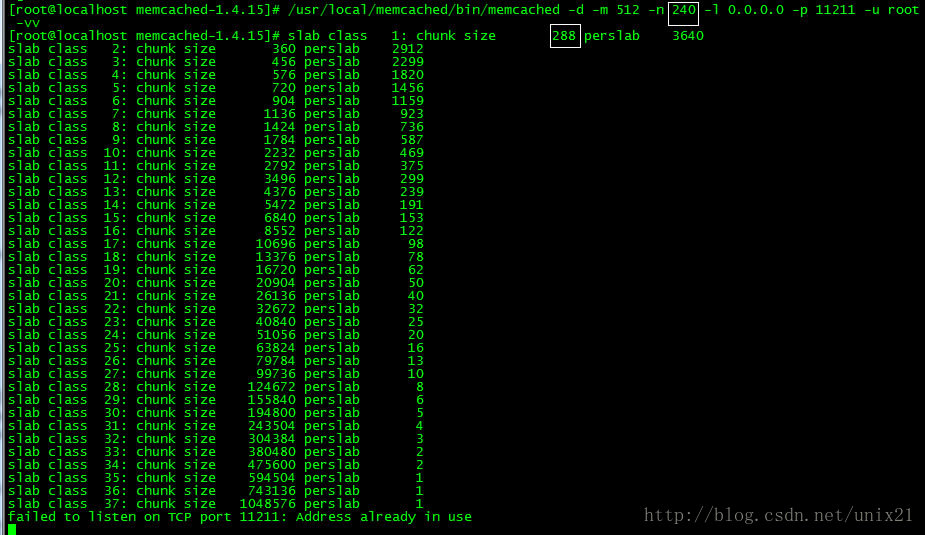
改为240
# /usr/local/memcached/bin/memcached -d -m 100 -n 240 -uroot -l 0.0.0.0 -p 11211 -c 512 -P /usr/local/memcached/memcached.pid -vv
# /usr/local/memcached/bin/memcached -d -m 512 -n 240 -l 0.0.0.0 -p 11211 -u root -vv
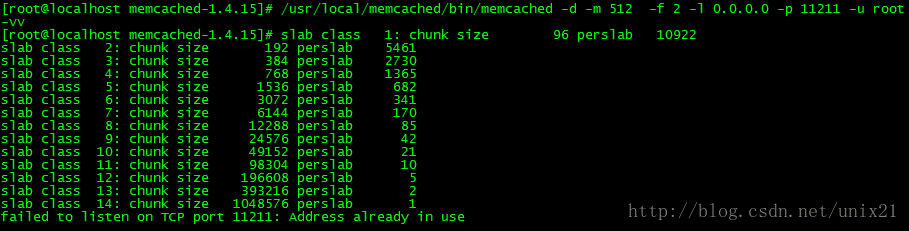
增长因子f默认是1.25,该值越小所能提供的chunk间隔越小,可以减少内存的浪费
# /usr/local/memcached/bin/memcached -d -m 512 -f 2 -l 0.0.0.0 -p 11211 -u root -vv
修改-I改变每个slab的大小:
第一次最大-I只有2048,然后改为4056
查看slabs状态
# stats slabs 显示各个slab的信息,包括chunk的大小、数目、使用情况等
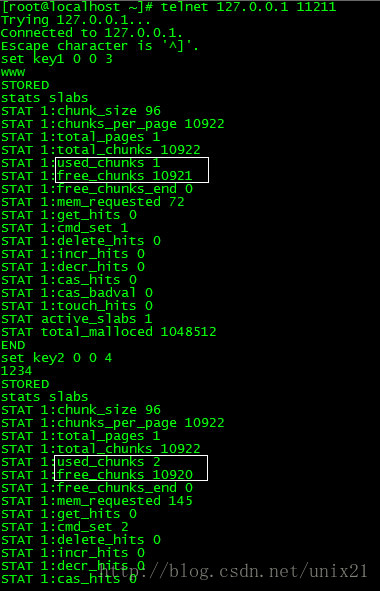
# telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
#
set key1 0 0 3 www STORED
#
get key1
需要注意的是set
最后一个参数就是
value字符的长度!
下面是故意构造多个不同chunk的字符存储效果
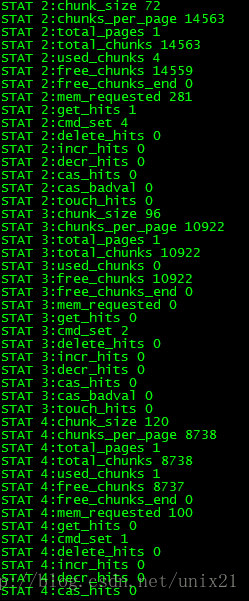
# stats
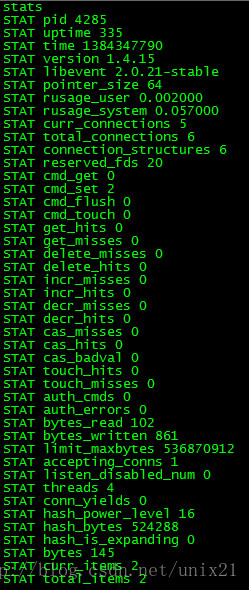
# stats items
调整slab参数 slab对于memcached的空间利用率占有决定因素.
-f:增长因子,chunk的值会按照增长因子的比例增长(chunk size growth factor).
-n:每个chunk的初始大小(minimum space allocated for key+value+flags),chunk大小还包括本身结构体大小.
-I:每个slab page大小(Override the size of each slab page. Adjusts max item size)
-m:需要分配的大小(max memory to use for items in megabytes)
chunk_per_page:每个page的chunk数量
total_chunks:chunk数量*page数量
free_chunks:曾经被使用,但是目前被回收的chunk数.
free_chunks_end:从来没被使用的chunk数
total_malloced:实际已分配的内存数.
unsigned int end_page_free; static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES];
slabs_init(const size_t limit, const double factor, const bool prealloc)
unsigned int size = sizeof(item) + settings.chunk_size;
//计算一个chunk的大小,包括item结构体本身的大小,key和value和flags的大小. mem_base = malloc(mem_limit); //一次性分配mem_limit大小的内存,并指向到mem_base指针中.
memset(slabclass, 0, sizeof(slabclass));//初始化为0
while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
if (size % CHUNK_ALIGN_BYTES) size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES); //字节对齐 slabclass[i].size = size; //这个slabs的大小 slabclass[i].perslab = settings.item_size_max / slabclass[i].size; //一共含有多少个chunk power_largest = i; //最后一个slabs.最多可以有MAX_NUMBER_OF_SLAB_CLASSES个
slabclass[power_largest].size = settings.item_size_max;
slabclass[power_largest].perslab = 1;
#ifndef DONT_PREALLOC_SLABS
char *pre_alloc = getenv("T_MEMD_SLABS_ALLOC"); if (pre_alloc == NULL || atoi(pre_alloc) != 0) { slabs_preallocate(power_largest); 5:do_slabs_newslab 初始化slabs
do_slabs_newslab(const unsigned int id) {
slabclass_t *p = &slabclass[id]; //对应第几个slabs int len = p->size * p->perslab; if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > 0) || (grow_slab_list(id) == 0) || ((ptr = memory_allocate((size_t)len)) == 0)) { memset(ptr, 0, (size_t)len); //初始化大小 p->end_page_ptr = ptr; //指向下一个空闲的page指针 p->end_page_free = p->perslab;//没有使用的chunk个数 p->slab_list[p->slabs++] = ptr; mem_malloced += len; //对mem_base指针的移动 }
//重新分配slabs个数,默认是分配16个页,后续按照2倍增加
static int grow_slab_list (const unsigned int id) {
slabclass_t *p = &slabclass[id]; if (p->slabs == p->list_size) { size_t new_size = (p->list_size != 0) ? p->list_size * 2 : 16; void *new_list = realloc(p->slab_list, new_size * sizeof(void *)); //重新realloc if (new_list == 0) return 0; unsigned int slabs_clsid(const size_t size) {
int res = POWER_SMALLEST; while (size > slabclass[res].size) if (res++ == power_largest) static void *do_slabs_alloc(const size_t size, unsigned int id) {
if (id < POWER_SMALLEST || id > power_largest) { assert(p->sl_curr == 0 || ((item *)p->slots[p->sl_curr - 1])->slabs_clsid == 0); if (mem_limit && mem_malloced + size > mem_limit) { if (! (p->end_page_ptr != 0 || p->sl_curr != 0 || do_slabs_newslab(id) != 0)) { } else if (p->sl_curr != 0) { ret = p->slots[--p->sl_curr]; //直接使用 assert(p->end_page_ptr != NULL); if (--p->end_page_free != 0) { p->end_page_ptr = ((caddr_t)p->end_page_ptr) + p->size;
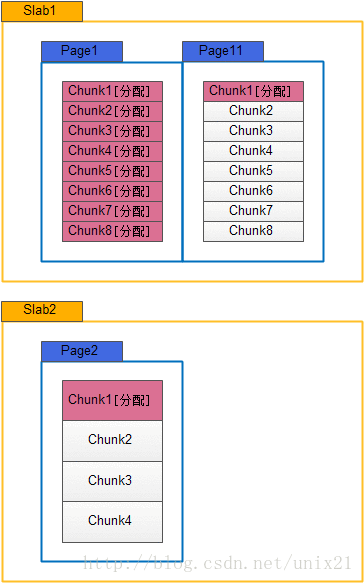
slab,是一个逻辑概念。它是在启动memcached实例的时候预处理好的,每个slab对应一个chunk size,也就是说不同slab有不同的chunk size。具体分配多少个slab由参数 -f (增长因子)和 -n (chunk最小尺寸)决定的。
page,可以理解为内存页。大小固定为1m。slab会在存储请求时向系统申请page,并将page按chunk size进行切割。
chunk,是保存用户数据的最小单位。用户数据item(包括key,value)最终会保存到chunk内。chunk规格是固定的,如果用户数据放进来后还有剩余则这剩余部分不能做其他用途。
工作流程:memcahed实例启动,根据 -f 和 -n 进行预分配slab。以 -n 为最小值开始,以 -f 为比值生成等比数列,直到1m为止(每个slab的chunk size都要按8的倍数进行补全,比如:如果按比值算是556的话,会再加4到560成为8的整倍数)。然后每个slab分配一个page。当用户发来存储请求时(key,value),memcached会计算key+value的大小,看看属于哪个slab。确定slab后看里面的是否有空闲 chunk放key+value,如果不够就再向系统申请一个page(如果此时已经达到 -m 参数设置的内存使用上限,则看是否设置了 -M 。如果设置了 -M 则返回错误提示,否则按LRU算法删除数据)。申请后将该page按本slab的chunk size 进行切割,然后分配一个来存放用户数据。
1,chunk是在page里面划分的,而page固定为1m,所以chunk最大不能超过1m。
2,chunk实际占用内存要加48B,因为chunk数据结构本身需要占用48B。
3,如果用户数据大于1m,则memcached会将其切割,放到多个chunk内。
1,-n 参数的设置,注意将此参数设置为1024可以整除的数(还要考虑48B的差值),否则余下来的部分就浪费了。
2,不要存储超过1m的数据。因为要拆成多个chunk,计算和时间成本都成倍增加。
3,善用stats命令查看memcached状态。
4,消灭eviction(被删除的数据)。造成eviction是因为内存不够,有三个思路:一是在CPU有余力的情况下开启压缩(PHP扩展);二是增加内存;三是调整 -f 参数,减少内存浪费。
6,缓存小数据。省带宽,省网络I/O时间,省内存。
7,根据业务特点,为数据尺寸区间小的业务分配专用的memcached实例。这样可以调小 -f 参数,使数据集中存在少数几个slab上,内存浪费较少。
Memcached的内存分配以page为单位,默认情况下一个page是1M ,可以通过-I参数在启动时指定。如果需要申请内存 时,memcached会划分出一个新的page并分配给需要的slab区域。Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储,其大小可以通过启动参数设置增长因子,默认为1.25,即下一个slab的大小是上一个的1.25倍。 
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。
如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如 果没有则要进行申请。slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到 page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储 数据。如下图,slab 1和slab 2都分配了一个page,并按各自的大小切分成chunk数组。
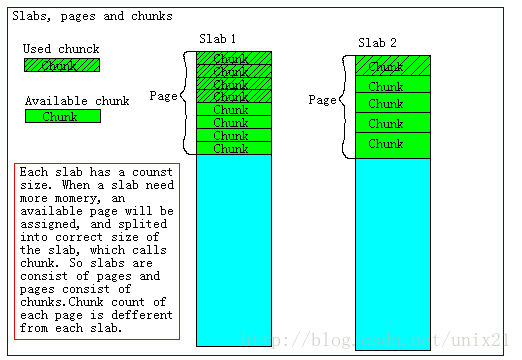
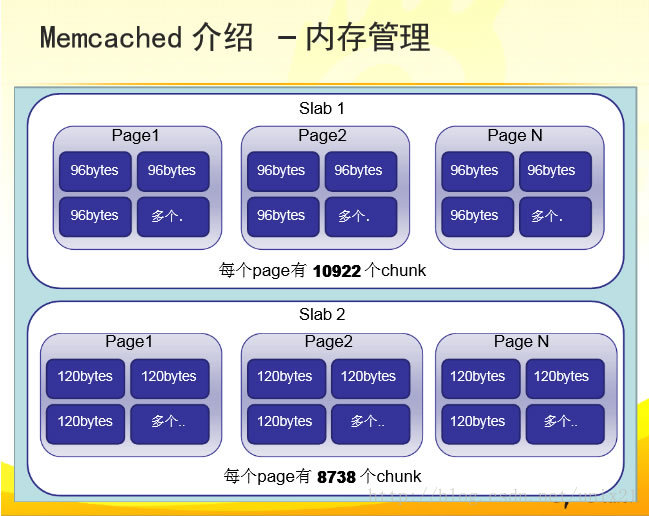
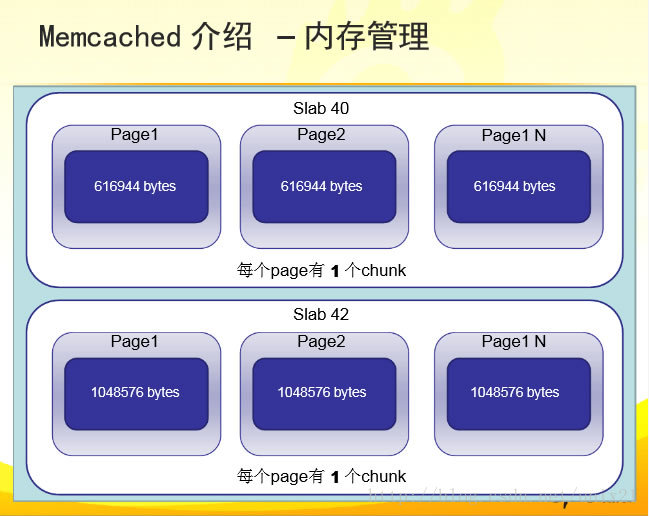
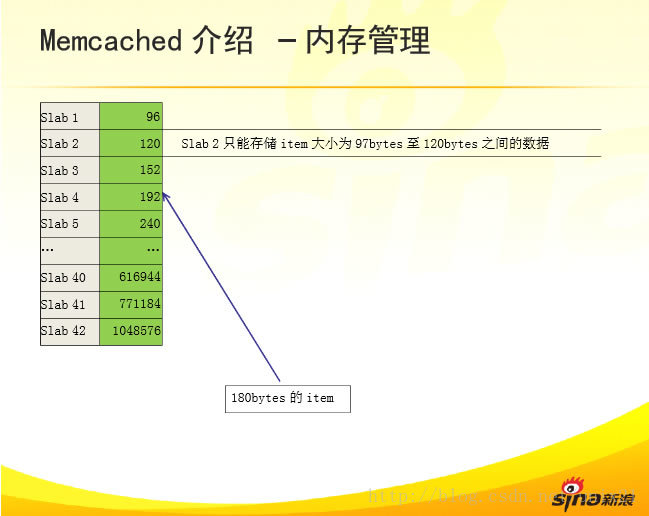
默认情况下memcached把slab分为42类(class1~class42),在class 1中,chunk的大小为96字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有10922个chunk:
在class1中,剩余的16字节因为不够一个chunk的大小(80byte),因此会被浪费掉。每类chunk的大小有一定的计算公式的,假定i代表分类,class i的计算公式如下:
chunk size(class i) : (default_size+item_size)*f^(i-1)+ CHUNK_ALIGN_BYTES
- default_size: 默认大小为48字节,也就是memcached默认的key+value的大小为48字节,可以通过-n参数来调节其大小;
- item_size: item结构体的长度,固定为32字节。default_size大小为48字节,item_size为32,因此class1的chunk大小为48+32=80字节;
- f为factor,是chunk变化大小的因素,默认值为1.25,调节f可以影响chunk的步进大小,在启动时可以使用-f来指定;
- CHUNK_ALIGN_BYTES是一个修正值,用来保证chunk的大小是某个值的整数倍(在32位机器上要求chunk的大小是4的整数倍)。
从上面的分析可以看到,我们实际可以调节的参数有-f、-n,在memcached的实际运行中,我们还需要观察我们的数据特征,合理的调节f,n的值,使我们的内存得到充分的利用减少浪费。
•Memcached 采用slab+page+chunk 方式管理内存
–Slab,特定大小的一组chunk
–Page,每次分配给slab的内存空间,会按照slab大小切分为chunk(默认1MB)–Chunk,存储记录的内存空间
存储一个value的大体过程
1.先根据要存储的key、value和flags计算item的大小
item长度=item结构大小 + 键长 + 后缀长 + 存储值长度
2.如果这个item对应的slab还没有创建,则申请1个page(默认1MB),将这个page按照这个slab类chunk的大写进行分割,然后将这个 item 存入
3.如果存在,且对应的slab没用完,存储
4.如果存在,且对应的slab用完了,则看内存是否用完,用完则启用LRU,否则申请新的page,存储
在make的时候增加参数: 如果之前已经安装需要清理,
必须加上编译选项-O0,不然在gdb内打印变量时提示"<value optimized out>"
# make uninstall
#
make CFLAGS="-g -O0" #
make install 在gdb里启动 #
gdb /usr/local/memcached/bin/memcached 给gdb传参数 带精灵模式
# set args -d -m 100 -uroot -l 0.0.0.0 -p 11211 -c 512
不带精灵模式 #
set args -m 100 -uroot -l 0.0.0.0 -p 11211 -c 512 后面都是走正常的调试流程
# r
# break main
# break slabs_init
后面都是走正常的调试流程
# s 下一步 跟进函数
# n 下一步 不跟进函数
# c 下一个断点
修改变量值 修改do_daemonize,这样就不用进入daemon了
#p do_daemonize=0
 调试线程
调试线程 # info threads
显示进程中所有的线程的概要信息。gdb按顺序显示:
1.线程号(gdb设置)
2.目标系统的线程标识。
3.此线程的当前堆栈。
一前面打*的线程表示是当前线程。
#thread THREADNO
把线程号为THREADNO的线程设为当前线程。命令行参数THREADNO是gdb内定的
线程号。你可以用info threads命令来查看gdb内设置的线程号。gdb显示该线程
的系统定义的标识号和线程对应的堆栈。比如:

#thread apply [THREADNO] [ALL] ARGS
此命令让你对一个以上的线程发出相同的命令ARGS,[THREADNO]的含义同上。
如果你要向你进程中的所有的线程发出命令使用[ALL]选项。
无论gdb何时中断了你的程序(因为一个断点或是一个信号),它自动选择信号或
断点发生的线程为当前线程。gdb将用一个格式为[Switching to SYSTAG]的消息来向你报告。